Service Management
Behind every dashboard chart and every alert is a set of background services quietly doing the work: checking whether devices are reachable, polling them for metrics, and listening for the syslog and trap messages your equipment sends in. Service Management is the control panel where you can see all of those services at a glance, confirm they are healthy, and restart one if it gets stuck.
Open it from Configure → Service Management.
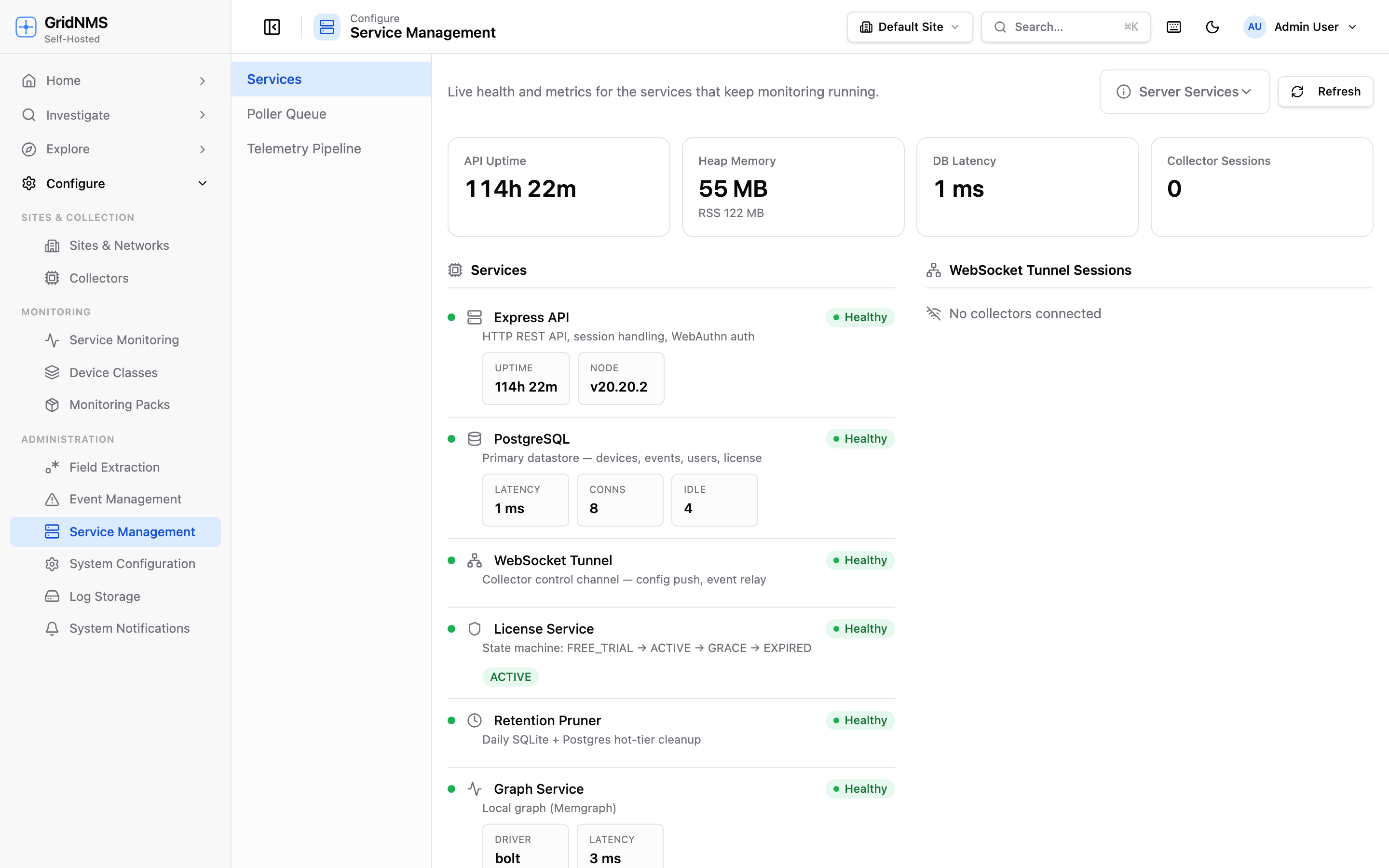 Service Management shows live health and uptime for each background service that keeps monitoring running.
Service Management shows live health and uptime for each background service that keeps monitoring running.
What you’re looking at
Section titled “What you’re looking at”The page is split into a few areas:
- Overview chips across the top — quick headline numbers like how long the service has been running, current memory use, response time to the database, and how many collectors are connected right now.
- Services list — one row per background service, each with a status light and a few key details.
- Connected collectors — the collectors currently linked to GridNMS, with how long each has been connected.
- Trend charts — small line charts showing the last hour of memory, database response time, event volume, and connected-collector count, so you can spot a problem building up over time.
The page refreshes on its own every few seconds, and there is a Refresh button in the top-right if you want to force an immediate update.
The services and what they do
Section titled “The services and what they do”Each row in the services list represents one job GridNMS runs continuously. In plain terms:
| Service | What it does for you |
|---|---|
| Request handler | Answers everything the GridNMS web app and your collectors ask for — loading pages, saving changes, signing in. If this is unhealthy, the app itself feels broken. |
| Database | The main store for your devices, events, users, and settings. Its response time is the single best indicator of overall health. |
| Collector channel | The always-on link between GridNMS and every collector you’ve installed. It’s how configuration is pushed out and how collected data and events come back. |
| Licensing | Tracks your subscription state and the limits that apply to your plan (for example, how many devices you can monitor). |
| Retention cleanup | Runs once a day to trim old, expired event history so storage doesn’t grow forever. |
| Topology service | Powers the network map and the “what else is affected” blast-radius view. |
Reading a service’s status
Section titled “Reading a service’s status”Every service row shows a coloured status indicator and a label:
- Healthy (green) — the service is running and responding normally. This is what you want to see across the board.
- Degraded (red) — the service responded, but something is wrong (for example, the database is slow or returning errors). Worth investigating.
- Unknown (grey) — GridNMS couldn’t determine the state, usually momentarily while it gathers a fresh reading. If a row stays grey, treat it like degraded.
Some rows expand to show extra detail. The database row, for example, shows its response time and how many connections are open; the licensing row shows your current plan state.
What healthy looks like
Section titled “What healthy looks like”On a well-running system you should expect:
- Every service row showing Healthy.
- Database response time steady and low (typically a few milliseconds), with a flat trend line rather than a climbing one.
- A steady, expected number of connected collectors — matching the collectors you actually installed.
- The event-volume chart tracking your normal traffic, not spiking to zero (which can mean data has stopped flowing) or far above normal (which can mean a storm).
When to restart something
Section titled “When to restart something”Restarting is a blunt but effective tool. Reach for it when a service is clearly stuck rather than as a first reflex. Good moments to restart:
- A service shows Degraded and stays that way after a couple of refreshes.
- The web app is sluggish or erroring and the database response-time chart is climbing steadily.
- A collector shows as connected here but isn’t sending any data — restarting the collector channel can re-establish a clean link.
- After a configuration change that the documentation says requires a restart to take effect.
To act on a service, open its row and use the controls offered there — typically Restart (stop and start again) and, where available, Stop / Start.
Reading the live activity
Section titled “Reading the live activity”The trend charts at the bottom act as a short-term flight recorder for the last hour. Use them to tell a one-off blip from a real trend:
- Memory climbing without ever falling can indicate a service that needs a restart.
- Database response time spiking and staying high points at a database under pressure — slow queries, too much load, or a storage problem underneath.
- Event volume dropping to nothing usually means data stopped arriving — check your collectors next.
- Connected collectors dropping unexpectedly means one or more collectors lost their link.
Typical scenarios
Section titled “Typical scenarios”“The web app is slow for everyone.” Check the database row and its response-time chart first. If response time is high and climbing, the database is the bottleneck. A restart of the request handler can clear a temporary jam; a persistent problem needs deeper investigation.
“Charts and alerts stopped updating.” Look at the connected-collectors count and the event-volume chart. If collectors dropped off or event volume fell to zero, the issue is almost certainly on the collector side rather than here.
“One service is stuck on Degraded.” Refresh once or twice to rule out a momentary reading. If it persists, restart that single service from its row and watch for it to return to Healthy.
Where to go next
Section titled “Where to go next”- Monitoring Your Collectors — health of each collector’s own reachability, polling, and log-receiving jobs.
- Poller Queue — see the queue of pending device polls and which collector is handling each.
- Troubleshooting — step-by-step help when something isn’t behaving as expected.